SciMingo helpt onderzoekers het juiste evenwicht te vinden tussen complexiteit en begrijpelijkheid in wetenschapscommunicatie. Zo leren we je hoe je mensen aanspreekt zonder afbreuk te doen aan je onderzoek. Als volleerde flamingo's, meesters in evenwicht 🦩
Hart- en vaatziekten voorspellen in een oogopslag
Scriptie
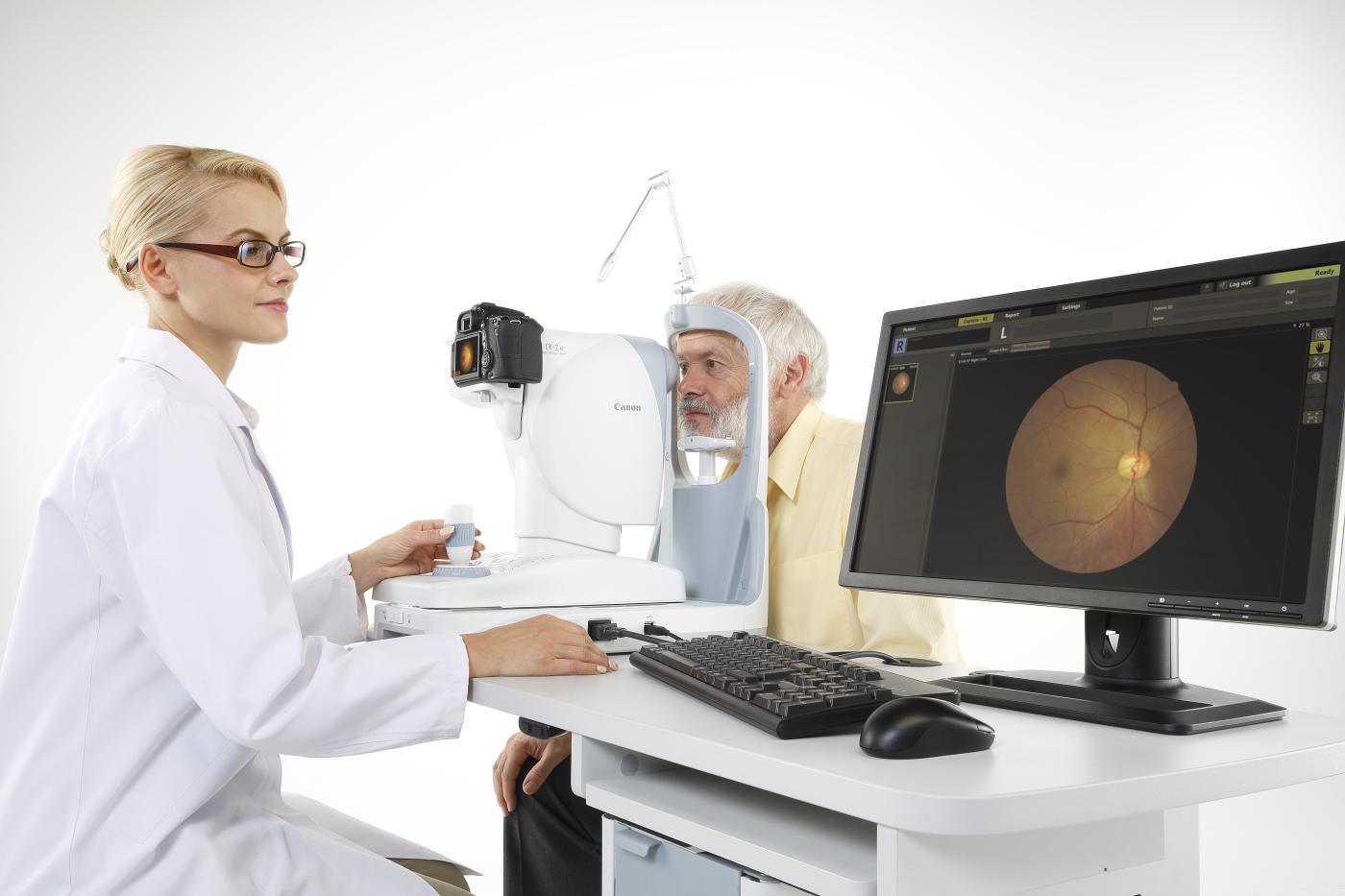
De impact van Artificiele Intelligentie (AI) groeit steeds sneller. Niet alleen in de ingenieurswetenschappen of spraaktechnologie, ook in de geneeskunde. Ruben Hemelings ging ermee aan de slag om via bloedvaten op het netvlies het risico op hart en vaatziekten op te sporen. Hemelings: “Bloedvaten ondergaan veranderingen als gevolg van diabetes, beroertes en Alzheimer. Dat maakt dat het tegenwoordig mogelijk is om via een foto het risico op hart- en vaatziekten op te sporen. Op dit moment is die complexe analyse van netvliesbeelden echter alleen weggelegd voor gespecialiseerde artsen.” Hemelings ontwikkelde een algoritme, een reeks instructies die je aan een computer geeft om een bepaald resultaat te bekomen, om een deel van het proces via artificiële intelligentie te automatiseren. Het algoritme is in staat slagaders en gewone aders in enkele seconden te identificeren op een foto van het netvlies, zonder de tussenkomst van een arts.
Brein
De software die het algoritme ontwikkelde doet beroep op een recente doorbraak in het domein van artificiële intelligentie, namelijk ‘deep learning’. Het principe achter deep learning steunt op de werking van neuronen in het menselijk brein: het systeem is georganiseerd in vele lagen van neuronen, waar elke volgende laag meer complexe informatie kan begrijpen en leren. Wanneer je bijvoorbeeld dit artikel leest, zie je in het begin onbewust ook enkel individuele letters, die dan opeenvolgend woorden, zinnen en alinea’s vormen, om dan uiteindelijk tot een geheel artikel te komen. Deep learning kan toegepast worden op foto’s en begrijpt in de beginlagen ook enkel individuele pixels. Daarna wordt de interpretatie van de pixels steeds nauwkeuriger waarna meer complexe structuren zoals randen en objecten worden aangeleerd in lagen aan het eind van het netwerk. Hoe meer voorbeelden de computer al eerder heeft gezien, hoe sneller en beter deze het object zal herkennen.
Het model komt erg dicht in de buurt van een menselijke expert
Van 20 naar 80.000 foto’s
“Momenteel is de toepassing van deep learning in de medische wereld nog beperkt omdat je een grote hoeveelheid gelabelde data nodig hebt voor het trainen van het model. In mijn onderzoek heeft het model een hoge prestatie kunnen bereiken met slechts twintig netvliesbeelden waar de twee verschillende soorten bloedvaten op aangeduid zijn door een gespecialiseerde arts. Wanneer ik deze beelden in hun oorspronkelijke vorm aan een deep learning-model zou invoeren, zou het model niet in staat zijn te ‘generaliseren’. Met andere woorden: het zou die twintig foto’s zo goed uit het hoofd leren, dat het perfecte accuraatheid scoort op diezelfde beelden, maar compleet zou falen wanneer er een ongeziene foto wordt aangeleverd. Door de aanwezigheid van vele lagen in het netwerk, is er een hoog aantal unieke trainingsbeelden vereist, zodat het netwerk niet uit het hoofd leert. Het grote struikelblok in mijn onderzoek was om met slechts twintig unieke gelabelde foto’s een zinvol model te trainen. De sleutel tot succes bleek data-augmentatie te zijn: originele foto’s omvormen tot een veelvoud aan ‘nieuwe’ foto’s. Door een foto te draaien of te spiegelen bijvoorbeeld, wordt dit door het deep learning-model beschouwd als een unieke foto. Daarnaast heb ik van de oorspronkelijke foto’s tal van kleinere beelden uitgesneden, wat uiteindelijk heeft geleid tot een verzameling van ongeveer 80.000 unieke beelden”, aldus Hemelings.
Op dit moment kan het model 98% van de primaire bloedvaten correct identificeren. Hiermee komt het model erg dicht in de buurt van een menselijke expert en laat het andere softwaretechnieken ver achter zich.
Dit artikel verscheen in de Vlaamse ScriptieKrant.
Meer weten? Lees de integrale scriptie in onze scriptiebank.
Deze scriptie werd geschreven onder begeleiding van Prof. Dr. Matthew Blaschko.








